
Getting data, part 1: reading a messy CSV, querying a database
Quite obviously, data science is not really possible without data. Before you can start munging your data, visualizing it, training models on it, you need to get your hands on it first. And that’s what this (and the following) post will be about.
Data in CSV files
Whether you’re learning Data Science and looking to practice your skills on something other than iris dataset,
or you need to find data that you think may be publicly available, there’s a good chance you can find a dataset in
.csv format.
On Kaggle (a website with tons of data science competitions) you can find a whole lot of datasets, and most of them are in csv format: https://www.kaggle.com/datasets You can also try your luck on Google Dataset Search.
Once you found your data, you can use pandas’ read_csv to create a dataframe for further manipulation.
In ideal world, reading a csv file would be as easy as:
import pandas as pd
df = pd.read_csv("my_data.csv")
Assuming my_data.csv is located in your current working directory, if not, you can specify any
path, or a URL to your csv file.
In reality, however, csv files are often messy, so you may need to skip the header, or get the encoding right. Pandas provide a whole lot of options to help you extract the actual data.
Here’s an example. Let’s take German census data for 2011 from https://www.govdata.de/
If we’ll try to simply read it without any options, we get a ParseError.
Turns out the first problem with this csv is that it uses ; as a separator. Let’s fix that:
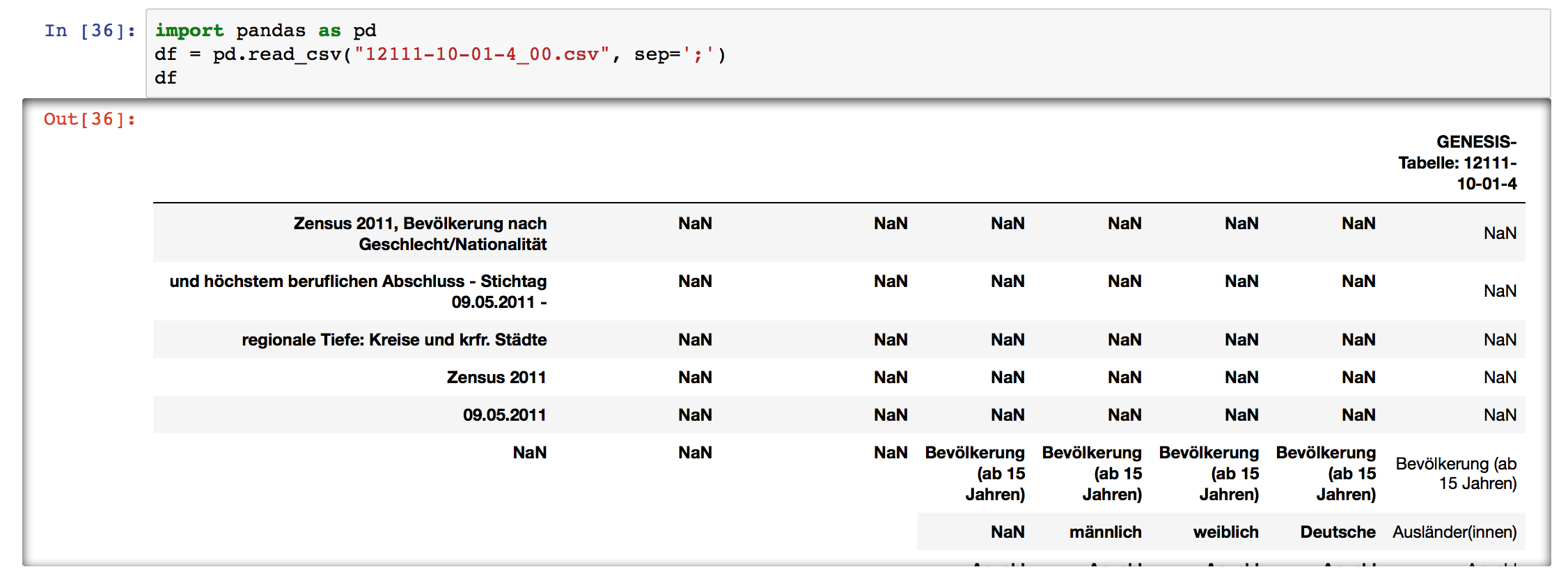
Now we can see that the top rows are just the description of the table and the summary, the three bottom rows have copyright data, the table has a multi-index, and pandas didn’t catch the column names, so let’s fix all of that too:
import pandas as pd
columns = ["id", "City", "Education", "Total population", "Men", "Women", "German citizens", "Immigrants"]
df = pd.read_csv("12111-10-01-4_00.csv", sep=';', skiprows = 13, skipfooter = 3,
names = columns, index_col = ["id", "City", "Education"])
At last, we get a nice DataFrame that we can work with!
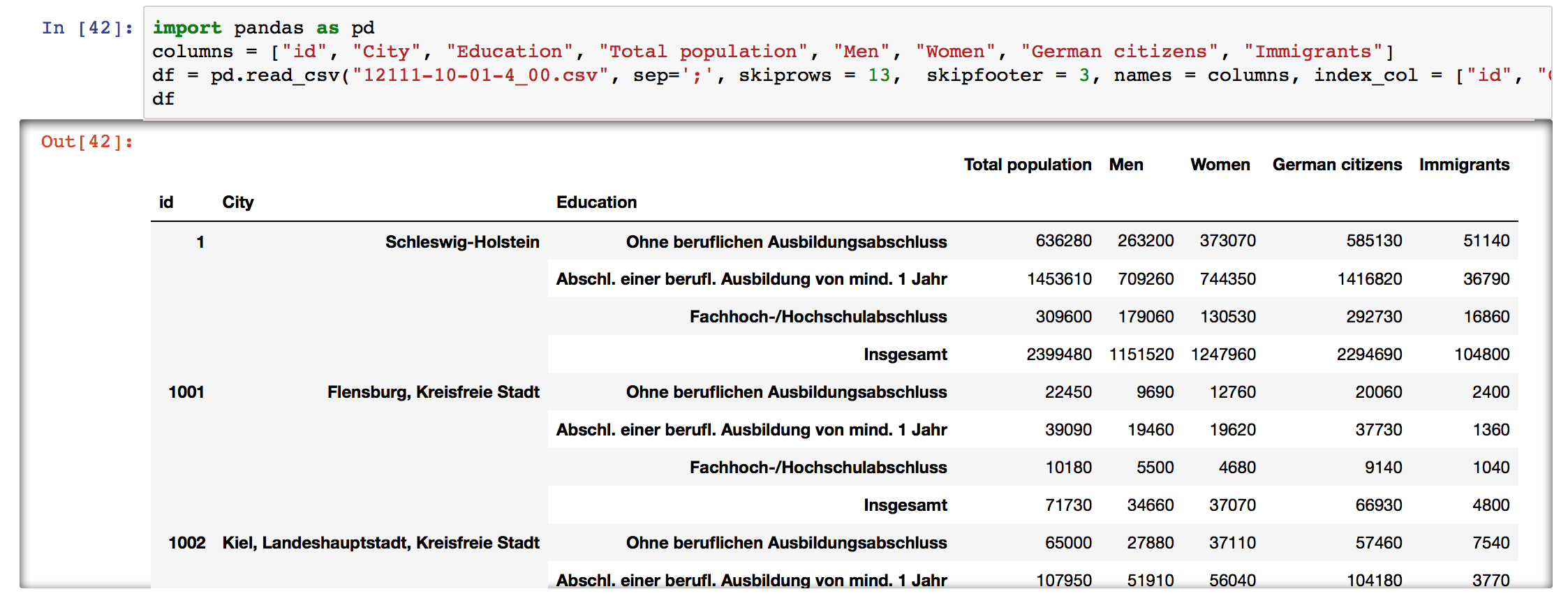
Fixing separator, skipping rows, giving names to columns, specifying index column (or a multi-index) are quite common things you’ll need to do when reading a csv. Often times you’ll also need to:
- Set the encoding, e.g.
encoding='latin1' - Parse the dates, e.g.
parse_dates=['Date'] - Specify only a subset of columns to use:
usecols = ["Men", "Women"] - Remove comments/metadata:
comment='#' - …
The list could go on - there are so many ways a csv file can be broken! Luckily, pandas have a huge set of options for dealing with all sorts of mess, and great documentation too!
Data in a database
If your data is stored in a database, you can get to it with Pandas as well. However, you’ll need to install some additional libraries first. Start by installing SQLAlchemy, it provides database abstraction. If you’re using SQLite, that’s it, no more tools needed, but if you’re using another database, you’ll need a driver library for it (for instance, PyMySQL for MySQL).
Once you have SQLAlchemy and the driver library installed (you can do it with pip install), you’ll need to create an
engine object to connect to your database using the the create_engine() function from SQLAlchemy:
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://admin:password@localhost:3030/mydatabase')
The typical form of a database URL looks like this:
dialect+driver://username:password@host:port/database
For more information on create_engine() and some examples, check out
the SQLAlchemy documentation.
Once you’ve created the engine, you can use pandas to get the data from your database.
You can use read_sql_table() to read a whole database or a subset of columns from a table:
pd.read_sql_table('data', engine)
Or you can query using raw SQL in the read_sql_query() function:
pd.read_sql_query('SELECT * FROM data', engine)
If you’re new to SQL, here’s some very basics of SQL querying to get you started:
SELECT id, name, occupation FROM data;
This will return the id, name, occupation columns from the data table.
SELECT * FROM data;
This will return all columns from the data table.
If you want to limit the number of rows returned, you can use the LIMIT keyword:
SELECT * FROM data LIMIT 1000;
If your data contains a lot of duplicate values and you want to get only unique values from a columns, use DISTINCT
keyword:
SELECT DISTINCT last_name FROM data;
You can also filter the results that you want to get from your database. You can use the WHERE keyword to do that.
For example, let’s get only records for a particular city:
SELECT * FROM data WHERE city = 'New York';
If you want to use several conditions, you can use AND keyword:
SELECT * FROM data WHERE city = 'New York' AND year > 2017;
You can add as many AND conditions as you need :)
If you want some of the conditions met, then use OR:
SELECT * FROM data WHERE city = 'New York' OR city = ‘Paris’;
You can combine AND and OR, but be sure to enclose the individual clauses in parentheses to make sure you get
the results you’re expecting:
SELECT * FROM data WHERE (year = 2007 OR year = 2017) AND (city = 'New York’ OR city = 'Paris');
To filter the data by a range of values use BETWEEN:
SELECT * FROM data WHERE year BETWEEN 2007 AND 2017;
Note that when using BETWEEN, the beginning and end values are included in the results.
You can also combine it with other conditions using AND/OR:
SELECT * FROM data WHERE year BETWEEN 2007 AND 2017 AND city = ‘New York’;
If you have many OR conditions, WHERE can get quite large. To avoid that, you can use WHERE IN:
SELECT * FROM data WHERE year IN (1997, 2007, 2017);
If you want to filter out missing (NULL) values, use the IS NOT NULL:
SELECT * FROM data WHERE city IS NOT NULL;
If you want to filter out the data based on a pattern rather than the exact match, you can use LIKE:
SELECT * FROM data WHERE name LIKE 'Mar%';
The % will match zero to any number of characters. So this will return all rows where a name starts with Mar, e.g. Maria, Marta, Mario, etc.
For a single character use _:
SELECT * FROM data WHERE name LIKE 'Mar_a';
This will return rows with names Maria and Marta but not Mario. If you want to return all except the rows with values matching the pattern, use NOT LIKE.
If you want to learn more about SQL querying, check out SQL Tutorial on w3schools.com. If you prefer books, try SQL Cookbook by Anthony Molinaro.
In both examples I looked at today the data already existed in a tabular format, and the goals was simply to read it into a pandas DataFrame. That’s not always the case, sometimes getting data is trickier, and you may need to do some web scraping, or get it via APIs. That’s what I plan to look into in the next post. Stay tuned!