
Getting data, part 2: web scraping and the walking dead
In my previous blog post I’ve talked about getting data from a csv file (even if it’s messed up), or a database. Sometimes the data you need isn’t that conveniently available for you to analyze and you need to get it first. One way to get the data you need may be to scrape it off of some website.
Before you do that, however, you need to check whether you are allowed to. Some websites may contain proprietary
information and strictly forbid scraping it, others don’t allow it because bots increase load on the servers causing issues.
Most websites allow scraping some of the content they have.The general rule here is to obey robots.txt that you can
find at [www.somewebsite.com]/robots.txt.
These files list the rules you need to follow, for example:
User-agent: *
Allow: /folder/
Disallow: /another_folder/file.html
User-agent: * means the rules apply to all bots, although sometimes bots are mentioned by name (you can find a lot
of such examples in https://en.wikipedia.org/robots.txt)
Allow and disallow rules can be very specific, stating a full path to a file, or whole sections of the site.
If you see something like this:
User-agent: *
Disallow: /
Steer clear from such site, as this means no scraping is allowed whatsoever.
Sometimes you will also see other restrictions:
Crawl-delay: 10means that you need to have a delay of 10 seconds when you’re crawling this site.Visit-time: 0400-0600means crawling is allowed between 04:00 and 06:00 UTC.Request-rate: 1/10is similar to crawl-delay. This means your bot can only crawl 1 page per 10 seconds.
Now, let’s get to an example. For this tutorial I’ve decided it would be fun to get some data on the characters from the Walking Dead TV Series. Wikipedia lists only main characters, IMDb doesn’t like crawlers (although the let you download IMDb’s plain-text data dump). I’ve found what seemed to be the most complete list of characters on walkingdead.fandom.com So that’s where we’ll be getting the data from.
Note: at the time of writing this post, their robots.txt allows scraping these pages, however, this can always change in the future, so make sure to double check it before scraping.
So how do we go about extracting the needed data from a web page? Well, we need to get the HTML page content and dig through it to get the information we need. Long-long time ago for a part of a student project I tried to write an HTML parser, and let me tell you, I got very close to throwing my computer out of the window. HTML is nasty, and there are all sorts of issues with it which your browser effectively handles, and you don’t even notice all the errors.
Luckily, we don’t have to manually clean up all the possible types of mess, as there is a nice library called BeautifulSoup that helps with that. I wish I knew of it back in the day!
We’re going to retrieve the pages with the requests library (pip install requests), which is a nicer way of making HTTP requests than what’s
built in, then we’re going to parse them with BeautifulSoup (pip install beautifulsoup4) and html5lib parser (pip install html5lib), and get a nice structured object to work with.
Now, we’re set and we can start poking at the content. Let’s first take a look at a single page with a character, for example, Morgan Jones.
from bs4 import BeautifulSoup
import requests
html = requests.get("https://walkingdead.fandom.com/wiki/Morgan_Jones_(TV_Series)").text
soup = BeautifulSoup(html, 'html5lib')
At this point we have a soup object and we can get quite a lot of information using just a couple of simple methods for
locating certain Tag objects: find and findAll.
To know which tags containg the data we need, let’s examine the character’s page.
Each character page has a side panel with the basic information about them like name, age, gender, occupation and so on,
and that’s the data we’d like to get. Let’s see what this panel looks like in html, in Chrome you can right click anywhere and
see the source with the Inspect option. Other browsers have similar actions.

We can see that the panel is in an aside tag, the character name is in an h2 tag, while the rest of the information
is in h3 and div tags with certain classes. Let’s search for them and extract the text content with text property
of a Tag object:
character = {}
character_info = soup.find('aside')
character["name"] = character_info.h2.text.strip()
items = character_info.findAll('div', "pi-item pi-data pi-item-spacing pi-border-color")
for item in items:
key = item.find('h3').text
character[key] = item.find('div', "pi-data-value pi-font").text
We end up with a dictionary that contains information on the character. But we’ll need to do it for all of them, so let’s make it a function:
def get_character_info(link_to_character_page):
html = requests.get(link_to_character_page).text
soup = BeautifulSoup(html, 'html5lib')
character = {}
try:
character_info = soup.find('aside')
character["name"] = character_info.h2.text.strip()
items = character_info.findAll('div', "pi-item pi-data pi-item-spacing pi-border-color")
for item in items:
key = item.find('h3').text
character[key] = item.find('div', "pi-data-value pi-font").text
except:
print("couldn't scrape: ", link_to_character_page)
return character
Next thing we need to do is get all the links to all the characters. The page listing all the characters is
https://walkingdead.fandom.com/wiki/TV_Series_Characters.
By inspecting this page, we can notice that all the links to characters have a class image image-thumbnail link-internal,
and the links end with TV_Series. These are the ones we need.
Don’t forget to set href to True if you want to get the actual links from a tags.
def get_links_to_characters(link):
wd_characters = []
html = requests.get(link).text
soup = BeautifulSoup(html, 'html5lib')
a_tags = soup.findAll('a', "image image-thumbnail link-internal", href=True)
for tg in a_tags:
if "TV_Series" in tg["href"]:
wd_characters.append("https://walkingdead.fandom.com" + tg["href"])
return wd_characters
There was one particular link that led to an obsolete page, so I ended up adding a little hack for that:
wd_characters = ["https://walkingdead.fandom.com/wiki/Jeffery_(TV_Series)" if x=="https://walkingdead.fandom.com/wiki/Jeffrey_(TV_Series)"
else x for x in wd_characters]
Now we just need to bring it all together, and write the data into a csv file as we go, so we could later analyze it. I’ve also added a delay, though I didn’t have to, I was just being nice :)
if __name__ == "__main__":
links_to_characters = get_links_to_characters(url)
with open('wd_char.csv', 'w', newline='') as csvfile:
fieldnames = ["name", "Actor", "Gender","Hair","Age","Occupation","Family","First Appearance", "Last Appearance",
"Death Episode", "Cause of Death", "Status", "Series Lifespan", "Ethnicity"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for link in links_to_characters:
char_data = get_character_info(link)
if not char_data: continue
else:
writer.writerow(char_data)
sleep(10)
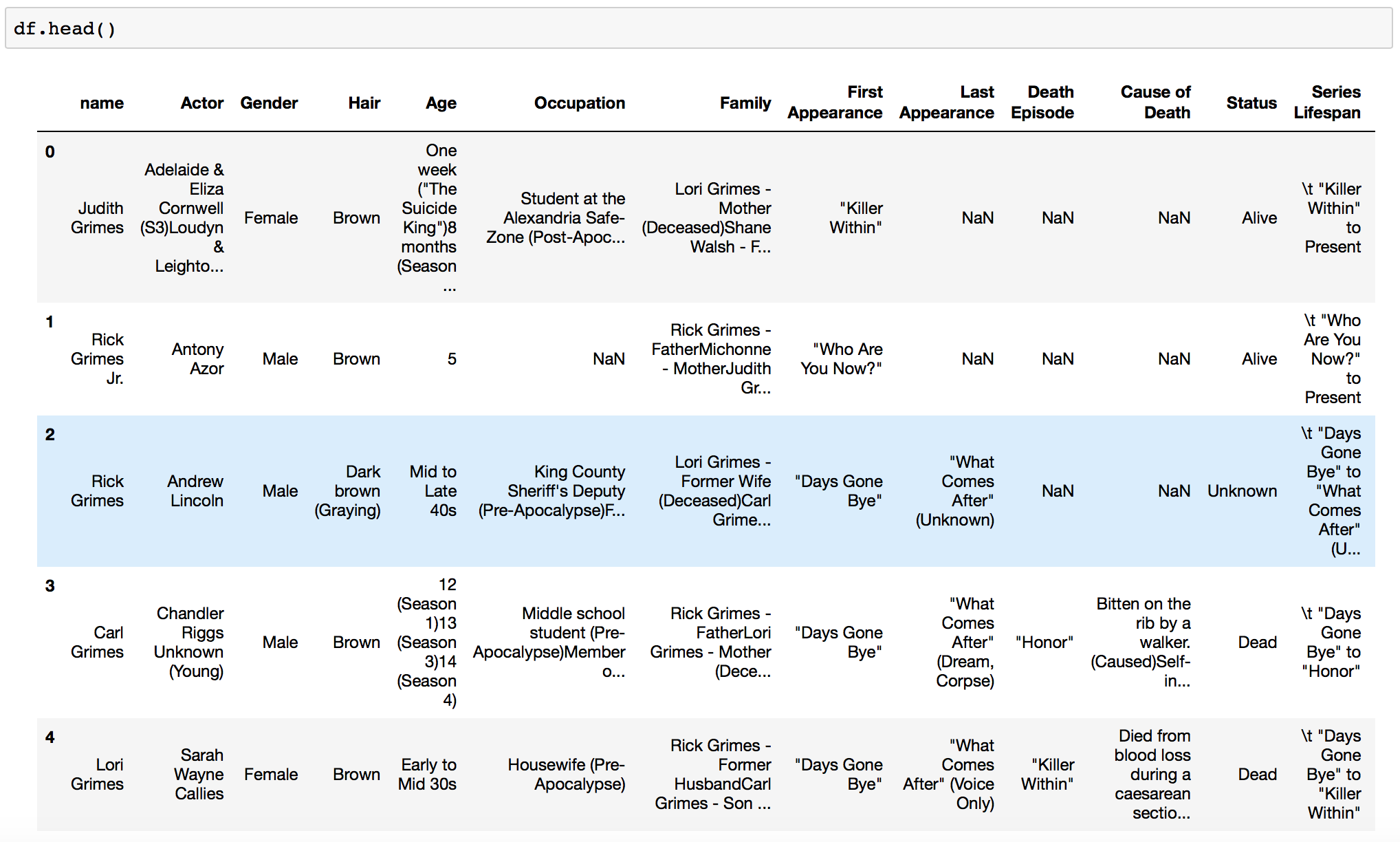
This little script gives us a nice csv with the data on each character that we can now use to make a pandas dataframe and have fun with:
To do some meaningful analysis however this data still needs a lot of cleanup, but that’s outside of today’s tutorial scope:)
If you want to play with the script, you can find it on github as well as the resulting csv.
Next time, let’s try to get some data via APIs.