
Pandas in anger
Pandas is an essential library in Data Scientist’s toolbox. If you’re just starting to learn, you’ll find a lot of great intro tutorials that’ll help you make your first steps with it. However, after a few of those steps and some practical experience you’re likely to find yourself confused by thing or two. Well, I did. And then I googled, flipped through docs and books, and prayed to stackoverflow gods until I figured those things out. To save you some time going through the same journey, I’ve compiled this post. As a bonus, at the end of it I’ve added a few tiny but neat pandas tricks that I find super useful.
Let’s jump right in.
df[“column”] vs df.column
TLDR; Use brackets, and you won’t need to worry if that will work or not.
Yes, this one seems super basic, but bear with me. There are two ways you can get the contents of a column from your
Data Frame as a Series object: df["column_name"] and df.column_name. Both are valid ways, and you’ll see some people
prefer one notation over the other.
However, if you prefer the dot notation because it saves you some typing, it’s good to be aware that it won’t always work. For instance, when your column name is a variable, e.g. you do something with your data frame in a function, or simply iterate through columns.
columns_to_iterate_through = ["column_1", "column_2", "column_3"]
for col in columns_to_iterate_through:
# do_something_with(df.col) won't work because it'll be looking for a column "col"
do_something_with(df[col])
Another case when dot notation won’t work is when the column name happens to have a name that’s the same as a data frame method. It’s not as common for me as the previous case but it can happen. For these reasons I made it a habit to use square brackets notation at all times.
loc vs iloc vs ix
TLDR; Use loc if you’re referring to indices as to labels: loc[0:5] returns rows starting with label “0” to label “5”. There may be less than 5 of them. Use iloc if you’re referring to row positions: iloc[0:5] returns rows from 0th to 4th (non-inclusive). Don’t use ix: it’s deprecated.
This was definitely a source a confusion for me in the beginning. Why are there several of them? What’s the difference? When do I prefer one over the others?
.loc uses the explicit index, meaning it treats the index as labels. .iloc on the other hand is implicit Python-style index, it is integer position based (from 0 to length -1 of the axis).
It is much more intuitive when you have a non-integer index in your Data Frame. Like this one:

In this case df.loc["New York"] returns the row where “New York” is the index, while df.iloc["New York"]
will throw an exception because iloc needs an integer position.

If I wanted to get the first row in this data frame I would need to use iloc: df.iloc[0]
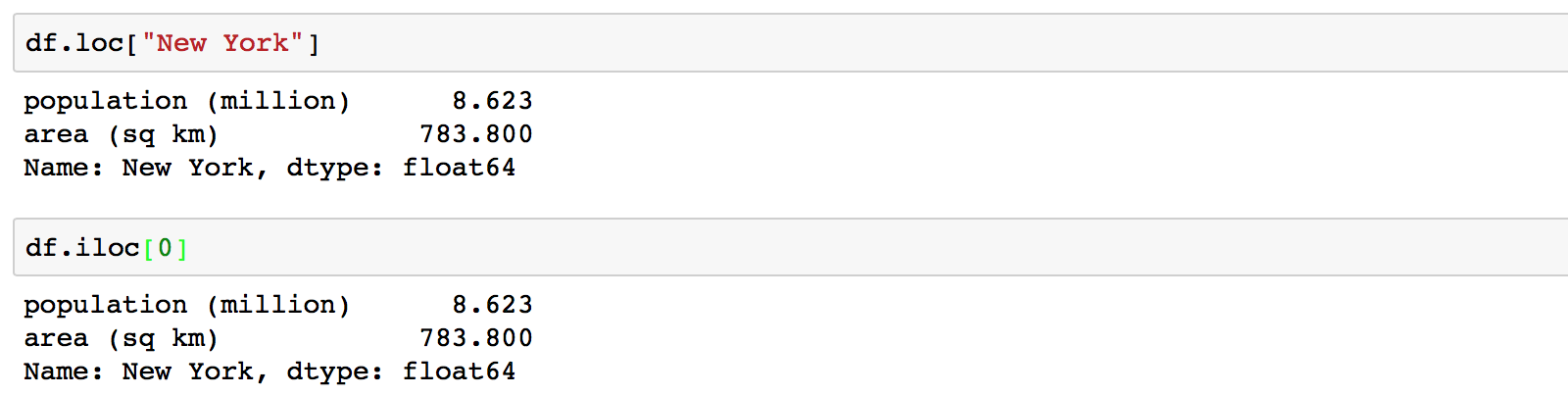
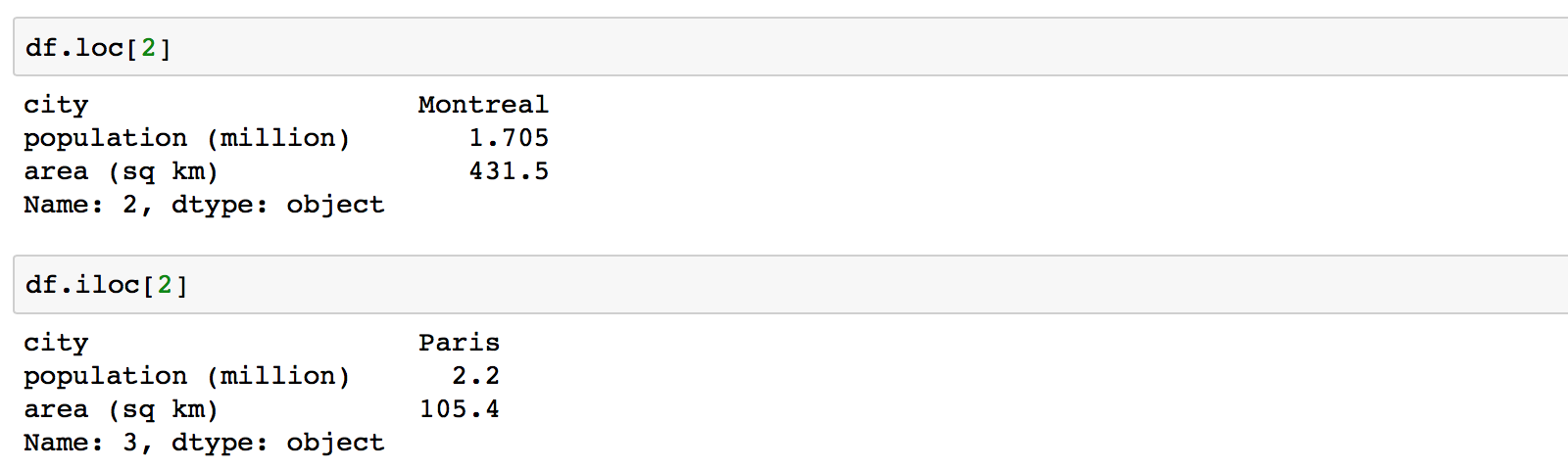
Most of the confusion arises of course when the index is integer.
Now df.loc[2] will return Montreal as it looks for an index label “2” in the data frame, while df.iloc[2]
will return Paris, as it’s the third element.
.apply vs .transform vs .agg
Figuring out the difference between these cost me a good number of hours going through pandas documentation and stackoverflow, because to be honest, the naming doesn’t give me clues on what’s the difference (especially between .transform and .apply), and it turns out to be quite subtle.
All three are used to apply functions to pandas objects. This means you can use them on Data Frames, Series and GroupBy Objects, here I’ll focus on Data Frames and GroupBy objects.
.apply vs .transform vs .agg with DataFrames
TLDR; To apply a function to a Data Frame use .apply(). Unless you want to apply multiple functions. In that case use .agg() to apply multiple aggregate functions, and .transform() for any other functions.
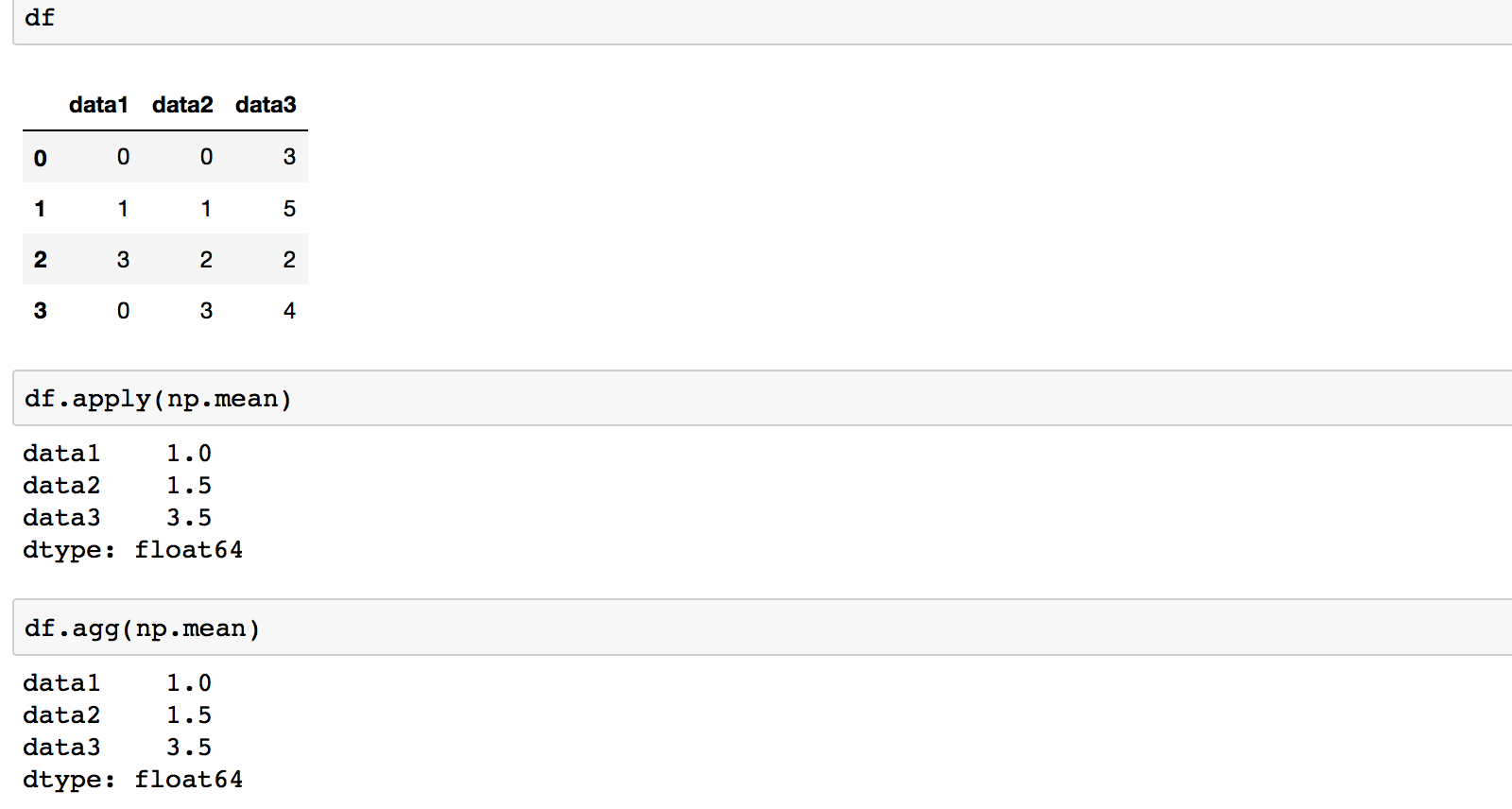
When using on a Data Frame with a single function that produces an aggregated result .apply and .agg are the same.
.transform won’t work with an aggregate function, as it’s meant to keep the original size of the Data Frame.
If the function being applied is not an aggregate one, all three methods yield the same result.
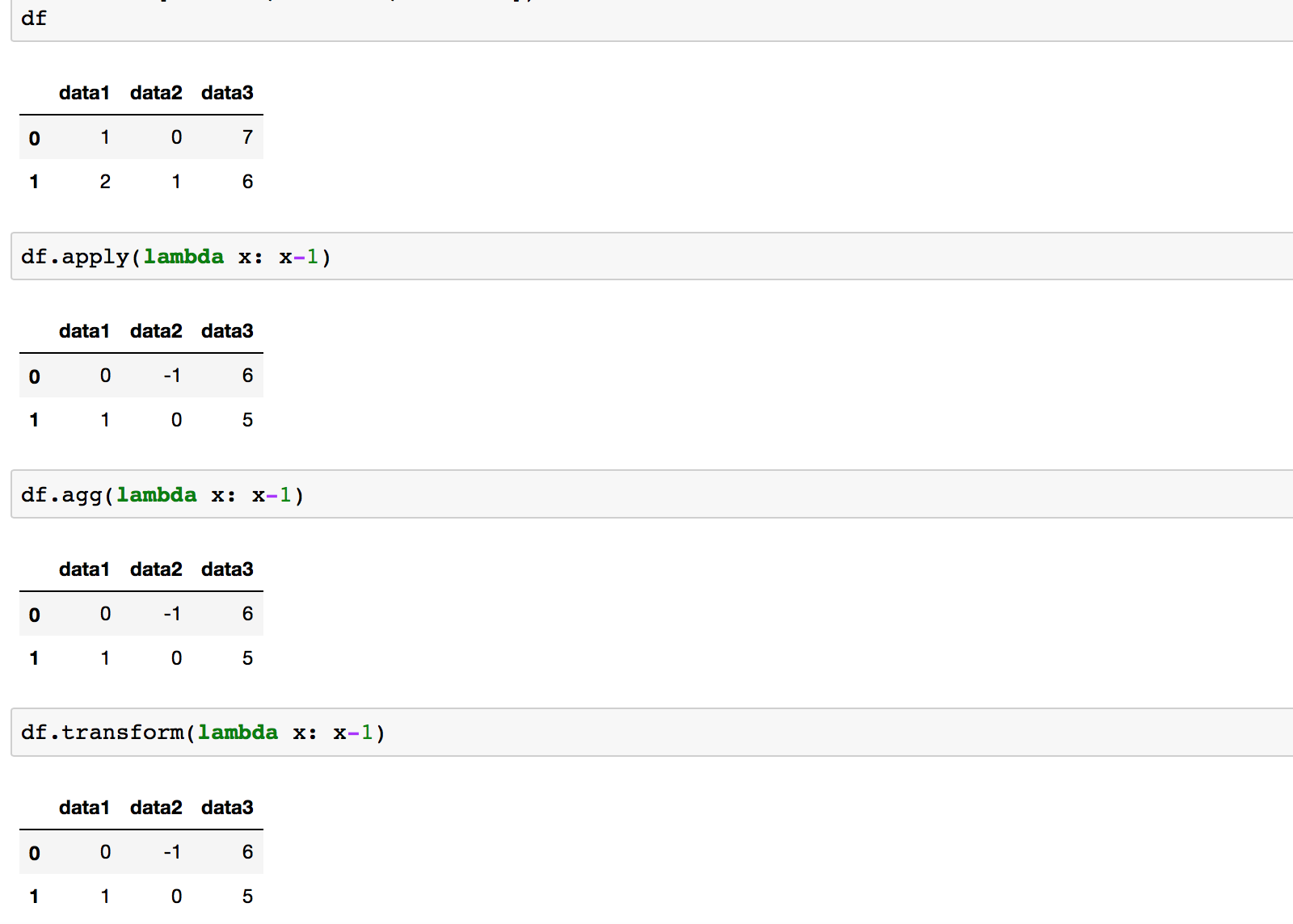
The important thing to remember here about the .apply is that the returned result depends on the passed function. If the function returns a Series object, then df.apply(function) will return a dataframe where that function was applied column-wise by default. If the function returns anything else (e.g. scalar as with np.mean), then df.apply(function) will return a Series.
If the function you pass to df.apply() takes arguments, you can pass them too. So whenever I need to apply a function to a Data Frame column-wise, my go to is .apply().
When would you use .agg and .transform then? These two are useful when you want to apply multiple functions. Go with .agg() if those functions are aggregates, and with .transform for the rest.
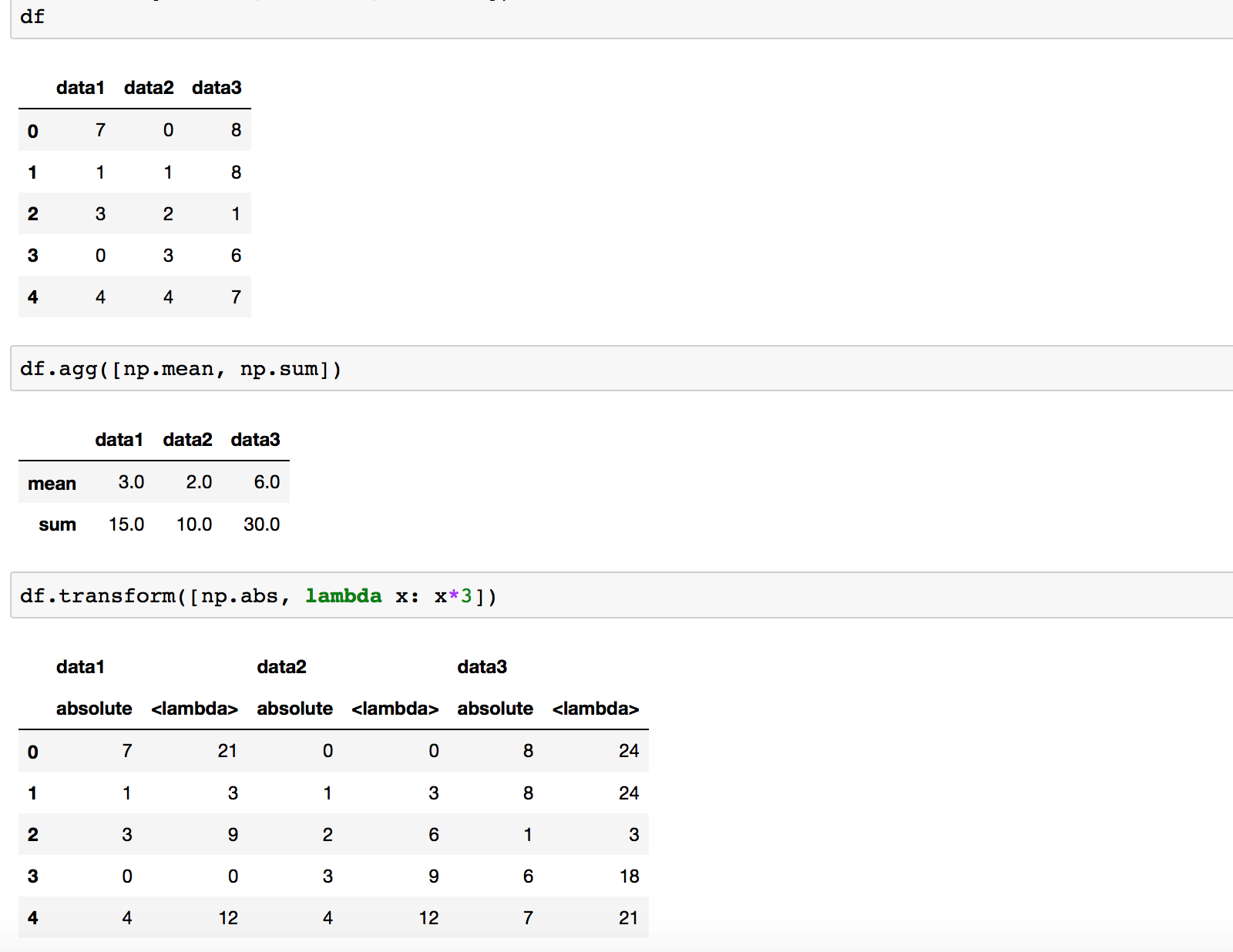
.apply vs .transform vs .agg with GroupBy
TLDR; When in doubt whether to use .apply or .transform on a GroupBy object, you most likely need .transform.
Now, let’s look at how .apply and .transform behave with another important pandas object - GroupBy.
When you call .groupby(“key”) on your DataFrame, you’re not creating a new DataFrame. What you get is a GroupBy Object which is sort of a view of your DataFrame that “splits” it into groups by “key”. No actual computation happens at this point, and to get a result, you need to specify what operation should be applied to this object for the actual computations to happen and to get a combined result. You can use any aggregate function here, like .sum() or mean(), and you can also use such GroupBy methods as aggregate, filter, transform and apply. While aggregate and filter seem intuitive to me, the transform and apply, yet again, do not.
So what are the differences between .transform and .apply?
First, .transform operates on a single column (a Series) at a time, you cannot, for instance, subtract a value of one column from another via transform. .apply passes all the columns for each group as a DataFrame to the custom function.
Second, .transform will always return a Data Frame of the original size (before grouped). This means that the function being applied with transform on a GroupBy object has to return the same-sized output as input, or broadcastable output (e.g. scalar). .apply on the other hand can returned a result of a different shape, e.g. aggregated.
The main power of the transform is that it can broadcast the results of a reduction function back to the original shape. This comes very handy for replacing missing data with the mean/median by groups.
For instance, let’s say we want to replace missing salaries with a mean of the neighborhood where a person lives.
df["Salary"] = df.groupby("Neighborhood")["Salary"].transform(lambda x: x.fillna(x.mean()))
When would one use .apply on a GroupBy object? According to the documentation, you only may need it in some exceptional cases, and to be honest, I personally didn’t encounter a case where I would have to use .apply with a groupby object.
Alright, this post is already getting quite long, so I’ll wrap it up with a few random small tricks.
Bonus tips
Want to see percentages instead of actual value counts for your categoricals?

Sort DataFrame by a value in a column. Why? For example, it can be handy to sort a Data Frame by date so that you can pick better test/validation sets.
df.sort_values(by='date', ascending=False)
Annoyed by Jupyter not displaying all the columns of your Data Frame when pretty-printing? You can change the max columns shown.
pd.set_option('display.max_columns', 999)
How about you? What was/is confusing you when using pandas in anger? What useful tricks can you share?