
Part of speech tagging with Hidden Markov Model in Kotlin
In NLP, part-of-speech tagging is a process in which you mark words in a text (aka corpus) as corresponding parts of speech (e.g., noun, verb, etc.). This task is fundamental to natural language processing and has multiple applications, for instance, Named Entity Recognition, or Word Sense Disambiguation.
The task may seem straightforward at first glance, but it becomes difficult when you realize that some words can be ambiguous, and their part-of-speech tag depends on the context. For example, take the word “sleep”. In a sentence “I plan to sleep until lunchtime tomorrow.”, this word is a verb. However, in the sentence “How much sleep does one really need?”, it is a noun.
How do you go about this problem? We can group the most commonly used approaches into two categories:
- Probabilistic methods: In these methods, you assign a tag based on the probability of it occurring in a given sentence. One of such approaches uses Hidden Markov Models, and that’s what this post covers.
- Deep Learning methods: Getting state-of-the-art results requires complex recurrent neural networks, such as Meta-BiLSTM Model described in this paper.
In this post, I’ve chosen to cover Hidden Markov Models for a couple of reasons. First, these models are amazingly versatile, and part-of-speech tagging is only one of their applications. Others include signal processing, speech recognition, handwriting recognition, musical score following, and much more… Perhaps, once you know how Hidden Markov Model works, you’ll find your own application for it! Second, the algorithm used for retrieving tag predictions, the Viterbi algorithm, didn’t click with me at first, and I had to spend some time building the intuition for it. So if my explanation helps you understand it, I would have saved you some time :) Finally, if you really would rather read about Deep Learning, don’t worry, I’ll be digging into some version of LSTM in one of the latter articles.
So here’s what you’ll learn from this post:
- What is Markov Model?
- What is Hidden Markov Model?
- How to prepare data
- Calculating Transition and Emission Matrices
- Motivation for Viterbi algorithm
- Viterbi initialization
- Viterbi forward pass
- Viterbi backward pass
Let’s start with what Markov Chains are.
Markov Model
A Markov chain is a mathematical system that transitions from one state to another according to certain probabilistic rules. An important property of this system (also called “Markov property”) is that the probability of transitioning to any particular state depends solely on the current state.
Let’s illustrate this with a toy example. Suppose, every day we observe the weather, and it is always one of the following: sunny, rainy, or cloudy (and for simplicity no other weather conditions exist). These are called states. Day after day we note it down, and as such, we create a sequence of observations. We can describe this situation with a Markov model:
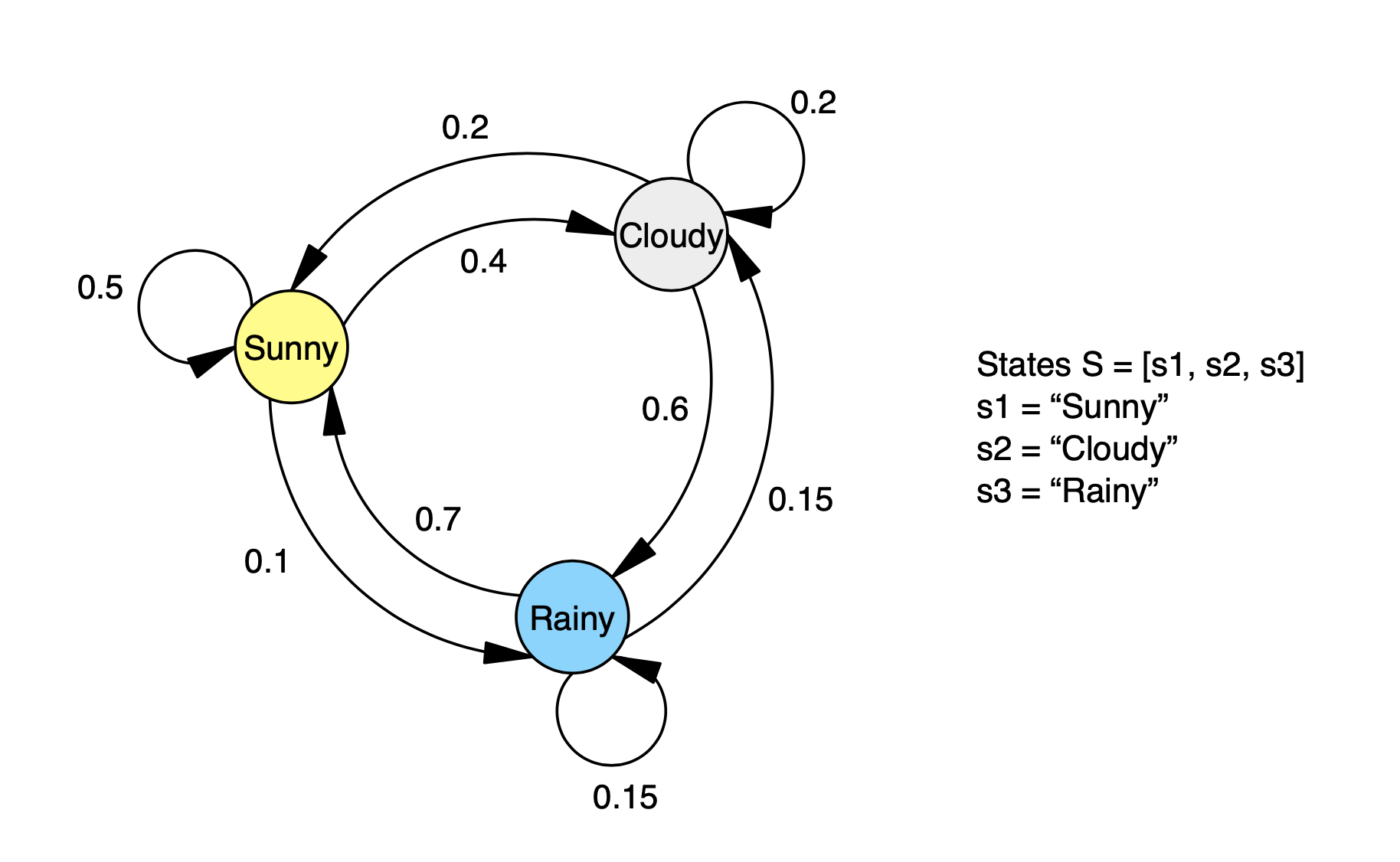
Each day we are in one of the states - it’s either sunny, rainy, or cloudy, and every day we transition into another state. If it’s sunny two days in a row, it means that we transition from state “sunny” to itself, but the transition still happens. After collecting the weather observations for some time, we can calculate the probabilities of transitioning from one state to another (including into the same state). These are the numbers that you see on the transitions. For example, if it’s sunny today, the probability that it will be cloudy tomorrow is 0.4. And, according to the Markov property the weather (aka state) tomorrow depends only on the weather (aka state) today.
We can write all the transition probabilities from this Markov model as a matrix A:
| s1 (Sunny) | s2 (Cloudy) | s3 (Rainy) | |
|---|---|---|---|
| s1 (Sunny) | 0.5 | 0.4 | 0.1 |
| s2 (Cloudy) | 0.2 | 0.2 | 0.6 |
| s3 (Rainy) | 0.7 | 0.15 | 0.15 |
In matrix A, a number in a cell $a_ij$ represents the probability of transitioning from state i to state j. Because a transition to some state has to happen (even if it is to itself), the numbers in each row must add up to 1.
Once we have modeled the weather like this, we can answer all sorts of questions. For example, if it has been sunny today, what is the probability that it will be sunny tomorrow? The answer to this you can simply look up in the matrix - 0.5 (50% chance). We can also answer more complex questions, like, if we have started with a sunny day, what is the probability to have the following sequence of days - [Sunny, Sunny, Rainy, Cloudy, Sunny]? This is where we would use the Markov property.
$$ P([s1, s1, s3, s2, s1] | Model ) = P(s1) * P(s1 | s1)*P(s3 | s1) * P(s2 | s3) * P(s1 | s2) $$
All these numbers except for the first one we have in the transition matrix A, and the first one we know from the problem statement (P(s1) = 1 because we started with a sunny day):
$$P([s1, s1, s3, s2, s1] | Model ) = 1 * a_11 * a_13 * a_32 * a_21 = 1 * 0.5 * 0.1 * 0.15 * 0.2 = 0.0015 $$
Now, this was a toy example to give you an intuition for the Markov model, its states, and transition probabilities. However, things are a little more complicated with Part of Speech tagging, and we will need a Hidden Markov Model.
Hidden Markov Model
In the previous examples, the states were types of weather, and we could directly observe them. The name “Hidden Markov Model” implies that we cannot directly observe the states themselves, but instead we can observe something else. Back to the Part of Speech tagging task, our hidden states will be parts of speech. So what is instead observed? The data that the algorithm will “see” is text - a sequence of words. These words are the actual observations from the data. How can we now model this situation? To simplify things let’s pretend we only have three hidden states - noun (NN), verb (VB), and other (O).
Just like in the previous example, we’re going to have a matrix with transition probabilities with a minor addition. Here, we’re also adding the initial state $pi$ and probabilities to transition from the initial state to any of the hidden states. These probabilities tell us how likely it is that the text begins with one of the given parts of speech.
![]()
In addition to this, a Hidden Markov Model has Emission probabilities - the probabilities to observe a word given hidden state. For example, given that we are currently in a “verb” state, here are the probabilities to observe each of the actual words in the corpus:

Here, you can see that if our model is in the VB (verb) state, there’s a 0.15 probability to observe the word “running”.
The emission probabilities can also be populated in a matrix (we’ll call it B), where rows represent each of the possible hidden states
(part of speech tags), and columns represent each of the possible observables (words). Thus, the size of this matrix would
be number of tags (states) by number of possible words. Just like with the transition matrix A, the sum of the
numbers in each row has to add up to exactly 1, as in each of the hidden states we have to observe one of the words.
This is how we can describe the corpus with words and POS tags with a Hidden Markov Model. Given a labeled corpus, “training” a Hidden Markov Model would mean populating the transition and emission matrices. Once that’s done, we can use those matrices for calculating predictions using the Viterbi algorithm.
We’ll get to the prediction part later in this article. First, let’s see how we can populate these matrices for actual labeled data.
Data & Some Preprocessing
The standard dataset that is used for training POS taggers for the English language is the Penn Tree Bank Wall Street Journal dataset. The corpus in it looks like this:
In IN
an DT
Oct. NNP
19 CD
review NN
of IN
'' ''
The DT
Misanthrope NN
'' ''
at IN
Chicago NNP
's POS
Goodman NNP
Theatre NNP
All words, punctuation marks, and other symbols are marked with corresponding tags, for example:
- IN: conjunction, subordinating, or preposition. Examples: of, on, before, unless.
- DT: determiner. Examples: the, a, these.
- NNP: noun, proper singular. Examples: Germany, God, Alice
- CD: cardinal number. Examples: five, three, 13%
- …and so on, check the complete description of what all the tags mean here.
As is the case with any machine learning project, we will use part of that data for training, and reserve the rest for evaluating the model.
To “train” a Hidden Markov Model and populate the transition and emission matrices, we will need to know what hidden states we have, and what words are in the corpus - the vocabulary.
To create the vocabulary, we’ll take the training chunk of the data, and record all the words that are encountered more than once. At the end of the words we will also add a list of special words: “–n–”, “–unk–”, “–unk_adj–”, “–unk_adv–”, “–unk_digit–”, “–unk_noun–”, “–unk_punct–”, “–unk_upper–”, “–unk_verb–”.
The first one, “–n–” is the special word for the initial state, the rest ("–unk–”, “–unk_adj–”, “–unk_adv–”, etc.) will replace the unknown words which we will inevitably encounter in both the training and the test corpus.
Here’s one way you can create the vocabulary:
import java.io.File
fun createVocabulary(trainingDataFile: File): List<String> {
/*
Creates vocabulary from the training data file.
The vocabulary includes all the words that are encountered more than once.
This is done so that unknown words would have some representation in the the training data as well.
The vocabulary is also appended with the list of various types of "unknown", and special "word" indicating
beginning of the sentence - "--n--"
*/
val lineList = trainingDataFile.readLines().filter { it != "" }
val words = lineList.map { getWord(it) }
val wordFrequences = words.groupingBy { it }.eachCount()
val vocabFromFile = wordFrequences.filter { (_, value) -> value > 1 }.keys.toList().sorted()
val unknowns = listOf(
"--n--", "--unk--", "--unk_adj--", "--unk_adv--", "--unk_digit--", "--unk_noun--",
"--unk_punct--", "--unk_upper--", "--unk_verb--"
)
return (vocabFromFile + unknowns).sorted()
}
private fun getWord(line: String): String {
var word = "--n--"
if (line.split('\t').isNotEmpty()) {
word = line.split('\t')[0]
}
return word
}
fun main() {
val trainingData = File("src/data/WSJ_02-21.pos")
val vocabulary = createVocabulary(trainingData)
File("src/data/vocab.txt").writeText(vocabulary.joinToString("\n"))
}
Now we are almost ready to start populating the transition and emission matrices. We only need a few functions that’ll help us go over the training data:
- We’ll need some heuristics to replace words that are not in the vocabulary with one of the “–unk_[]–” tokens
- As we will be calculating transition probabilities we’ll need to calculate how often each tag comes after another one, which means we’ll need to go through the training corpus line by line extracting both the word and the tag.
- Finally, when we’ll want to test our model, we’ll need to get just the words from the test corpus to generate part of speech predictions for them.
import java.io.File
object Preprocessor {
// heuristics for replacing words that are not in the vocabulary with unk-[...]
private val nounSuffix = listOf(
"action", "age", "ance", "cy", "dom", "ee", "ence", "er", "hood",
"ion", "ism", "ist", "ity", "ling", "ment", "ness", "or", "ry", "scape", "ship", "ty"
)
private val verbSuffix = listOf("ate", "ify", "ise", "ize")
private val adjSuffix = listOf(
"able", "ese", "ful", "i", "ian", "ible", "ic", "ish", "ive",
"less", "ly", "ous"
)
private val advSuffix = listOf("ward", "wards", "wise")
fun assignUnk(word: String): String = when {
word.contains(Regex("[0-9]")) -> "--unk_digit--"
word.contains(Regex("[^A-Za-z0-9 ]")) -> "--unk_punct--"
word.contains(Regex("[A-Z]")) -> "--unk_upper--"
nounSuffix.any { word.endsWith(it) } -> "--unk_noun--"
verbSuffix.any { word.endsWith(it) } -> "--unk_verb--"
adjSuffix.any { word.endsWith(it) } -> "--unk_adj--"
advSuffix.any { word.endsWith(it) } -> "--unk_adv--"
else -> "--unk--"
}
fun getWordAndTagFromLine(line: String, vocab: Map<String, Int>): Pair<String, String> =
if (line.split('\t').isNotEmpty() && line.split('\t').size == 2) {
var word = line.split('\t')[0]
val tag = line.split('\t')[1]
if (!vocab.containsKey(word)) word = assignUnk(word)
Pair(word, tag)
} else Pair("--n--", "--s--")
fun getTestWordsAndTags(vocab: Map<String, Int>, testDataFile: File): List<Pair<String, String>> {
val wordsAndTags = mutableListOf<Pair<String, String>>()
val lines = testDataFile.readLines()
for (line in lines) {
val (word, tag) = getWordAndTagFromLine(line, vocab)
if (word == "") {
wordsAndTags.add(Pair("--n--", "--s--"))
} else if (!vocab.containsKey(word)) {
wordsAndTags.add(Pair(assignUnk(word), tag))
} else wordsAndTags.add(Pair(word, tag))
}
return wordsAndTags
}
}
Calculating Transition and Emission Matrices
To populate these matrices, we will start with computing a few helper counts:
transitionCounts: amutableMapOf<Pair<String, String>, Int>()that will contain the number of times a sequence of two tags (tag_i, tag_j) has occurred in that order. We will use that count to later calculate the probability of transitioning from said tag_i to tag_j.emissionCountsamutableMapOf<Pair<String, String>, Int>()that will contain the number of times the word_k was came with tag_l. We will use these counts to calculate the emission probability of a word_k given tag_l.tagCounts: this map will simply store the number of times each tag occurred.
private fun calculateCounts() {
val preprocessor = Preprocessor
var previousTag = "--s--"
for (line in trainingCorpus) {
val (word, tag) = preprocessor.getWordAndTagFromLine(line, vocab)
transitionCounts[Pair(previousTag, tag)] = transitionCounts.getOrDefault(Pair(previousTag, tag), 0) + 1
emissionCounts[Pair(tag, word)] = emissionCounts.getOrDefault(Pair(tag, word), 0) + 1
tagCounts[tag] = tagCounts.getOrDefault(tag, 0) + 1
previousTag = tag
}
}
Now that we have all these counts, we can calculate the matrices themselves. For transition matrix, the formula is as follows:
$$P(t_i | t_{i-1}) = \frac{C(t_{i-1}, t_{i}) + \alpha }{C(t_{i-1}) +\alpha * N}$$
where:
- $C(t_{i-1}, t_{i})$ is the count of the pair (previous tag, current tag) in the
transitionCounts. - $C(t_{i-1})$ is the count of the previous tag in the
tagCounts. - $N$ is the total number of tags.
- $\alpha$ is a smoothing parameter. Smoothing is a technique that helps us to avoid shooting ourselves in the foot if some of those counts end up being 0. By adding $\alpha$ in the numerator and $\alpha * N$ in the denominator, instead of 0, we’ll end up with a very small number.
To work with matrices, I’m using multik, a multidimensional array library for Kotlin. It has been publicly released recently, and you can read more about it on the Kotlin blog.
private fun createTransitionMatrix(
alpha: Double = 0.001,
) {
val tags = tagCounts.keys.toList().sorted()
transitionMatrix = mk.empty<Double, D2>(NUMBER_OF_TAGS, NUMBER_OF_TAGS)
// Go through each row and column of the transition matrix
for (i in 0 until NUMBER_OF_TAGS) for (j in 0 until NUMBER_OF_TAGS) {
// Define the Pair (prev POS tag, current POS tag)
val key = Pair(tags[i], tags[j])
// If the (prev POS tag, current POS tag) exists in the transition counts dictionary, change the count
val count = transitionCounts.getOrDefault(key, 0)
// Get the count of the previous tag (index position i) from tag counts
val countPrevTag = tagCounts[tags[i]]
// Apply smoothing to avoid numeric underflow
transitionMatrix[i, j] = (count + alpha) / (alpha * NUMBER_OF_TAGS + countPrevTag!!)
}
}
Similarly, we calculate the probabilities for the emission matrix.
$$P(w_i | t_i) = \frac{C(t_i, word_i)+ \alpha}{C(t_{i}) +\alpha * N}$$
where:
- $C(t_i, word_i)$: the number of times $word_i$ was assosiacted with $tag_i$ in the training data (stored in
emissionCounts). - $C(t_i)$: the count of $tag_i$ in the
tagCounts. - $N$: total number of tags.
- $\alpha$: smoothing parameter.
private fun createEmissionProbsMatrix(
alpha: Double = 0.001
) {
val tags = tagCounts.keys.toList().sorted()
emissionProbsMatrix = mk.empty<Double, D2>(NUMBER_OF_TAGS, NUMBER_OF_WORDS)
val reversedVocab = vocab.entries.associate { (k, v) -> v to k }
for (i in 0 until NUMBER_OF_TAGS) for (j in 0 until NUMBER_OF_WORDS) {
val key = Pair(tags[i], reversedVocab[j])
val count = emissionCounts.getOrDefault(key, 0)
val countTag = tagCounts[tags[i]]
emissionProbsMatrix[i, j] = (count + alpha) / (alpha * NUMBER_OF_WORDS + countTag!!)
}
}
Once we have computed the Transition and Emission matrices we have described our data with a Hidden Markov Model, so we can pat ourselves on the back on this occasion - well deserved!
Now how can we use these matrices to predict POS tags for a sentence?
Viterbi Algorithm: Motivation
First, let’s define the problem we are trying to solve here. We have the Hidden Markov Model that contains information about the transition probabilities from each hidden state to another hidden state, and information about the emission probabilities from each hidden state to each word from the vocabulary.
Now we have a sentence (aka a sequence of words (= observations)), and we need to find the sequence of tags (hidden states) for this sentence that will yield the highest probability given this sequence of words. In other words, what sequence of tags matches this sentence the best?
The brute force method of answering this question would mean calculating probabilities for all the possible sequences of tags, and then choosing the one with the highest probability. However, ALL combinations of tags are possible (even if the probability for some is minuscule). So if we had a sentence with only 3 words, and there were only 4 possible tags - A, B, C, D, we would end up with 3^4 = 81 combinations to search through. In reality, we have 40+ tags, and sentences are typically much longer than 3 words. In general, for a sentence with N words, and T tags the search space of possible state sequences X is $O(N^T)$. As you can imagine this quickly becomes way too large to brute force search on.
Clearly, a smarter alternative is needed, and that’s where the Viterbi algorithm can help. The Viterbi algorithm is a Dynamic Programming algorithm that we will use for finding the most likely sequence of hidden states that results in a sequence of observations. Dynamic Programming is a method for solving a complex problem by breaking it down into a collection of simpler subproblems, solving each of those subproblems just once, and storing their solutions using a memory-based data structure. In this case, we’ll be taking advantage of knowing that an optimal state sequence X1 . . . Xj . . . XT contains a subsequence X1 . . . Xj, which is also optimal. With that, we’ll start building up the optimal sequence step by step, keeping record only of the best probabilities, and the path that got us there, not all the possible paths. This approach allows to bring the complexity down to $O(N^2 *T)$
As we will need to store intermediate results, we will need two additional matrices:
bestProbs: as we build up the optimal sequence, this is the matrix that will contain intermediate optimal probabilities.bestPaths: this matrix will hold the indices of visited states, so that once we finally find the best probability for the full sentence, we could traverse back thebestPathsto get the actual sequence of states that got us to the highest probability.
The Viterbi algorithm consists of three steps:
- Initialization. At this step we create the auxiliary matrices
bestProbsandbestPathsand populate the first column of each matrix. Both matrices will have the size ofNUMBER_OF_TAGSrows bysentence.sizecolumns. - Forward pass: We’ll be populating both matrices column by column, at each step finding the best probability and path for the current subsequence.
- Backward pass: Finally, we’ll use
bestPathsto backtrace the path that yielded the highest probability which we’ll get from the last column ofbestPathscorresponding to the last word in the sentence.
Let’s dive deeper in each of these steps.
Viterbi: Initialization
The first matrix we’ll be initializing is the bestProbs matrix. It has NUMBER_OF_TAGS rows and as many columns as we
have words in a sentence for which we need to predict the tags.
At this step we need to populate the first column, and leave the rest to be zeros.
The first column represents probabilities to emit the first word given each of the states when we start from the initial
state.
For example:
- bestProbs[1,1] is the probability to start in the hidden state T1 ( which is the same as transition from the initial state to the hidden state T1) and observe the word W1;
- bestProbs[2,1] is the probability to start in the hidden state T2 (aka transition from the initial state to hidden state T2) and observe the word W1;
- and so on
In general, bestProbs[i, 1] can be calculated as product of multiplying the probability to transition from the initial
state to hidden state $T_i$, and the probability to emit the word W1 given we are in hidden state $T_i$. One of these
numbers we have in the transition matrix, and the other one we have in the emission matrix.
To avoid the arithmetic underflow when dealing with extremely small probabilities, we’ll add the logarithm.
The bestPaths matrix should contain indices of all previously visited states, so for the first column everything is 0.
As a note, when creating an empty matrix with multik via mk.empty<Double, D2>(a,b) it already initializes to all zeros.
This means we only need to create an empty matrix of the required size at this step.
private fun initializeViterbiMatrices(
sentence: List<String>,
): Pair<D2Array<Double>, D2Array<Int>> {
/*
returns two matrices: bestProbs = best probabilities (num of states by num of words in sentence) and
bestPaths = best paths (num of states by num of words in sentence)
*/
val tags = tagCounts.keys.toList().sorted()
val bestProbs = mk.empty<Double, D2>(NUMBER_OF_TAGS, sentence.size)
val bestPaths = mk.empty<Int, D2>(NUMBER_OF_TAGS, sentence.size)
val startIdx = tags.indexOf("--s--")
// populating the first column of the bestProbs to initialize it
for (i in 0 until NUMBER_OF_TAGS) {
if (transitionMatrix[0, i] == 0.0) {
bestProbs[i, 0] = Double.NEGATIVE_INFINITY
} else {
bestProbs[i, 0] = ln(transitionMatrix[startIdx, i]) + ln(emissionProbsMatrix[i, vocab[sentence[0]]!!])
}
}
return Pair(bestProbs, bestPaths)
}
Once the matrices have been initialized, we can start populating them column by column in the forward pass. Remember, that each column represents the next word in the sentence. By moving from left to right column by column at each step we increase the subsequence in question by one word.
Viterbi: Forward Pass
In the forward pass we start populating the matrices column by column, storing the intermediate best probabilities in
bestProbs, and the path that got us there in bestPaths. Here’s how we calculate what should be in the cell [j,i]
where $j$ is the $Tag_j$ and $i$ is the $word_i$.
$$ bestProbs[j,i] = \max_{k}bestProbs_{k, i-1} * transitionMatrix_{k,j} * emissionMatrix_{j, {index of word i}}$$
To simplify, suppose we are calculating bestProbs for the third column. Here’s what we do here: We look at the previous (i.e. second) column and find the maximum value in it - this is a cell with the best probability for the previous subsequence. We take that number, and note the tag (k) at which we got the maximum value. That is the tag we will be transitioning from into our current, third column. So now for each tag in the third column we can multiply the best probability value we got for the previous subsequence by the probability to transition from previous best tag into this tag, multiplied by the probability to observe current column’s word given this tag.
At the same time, when calculating bestProbs, we’ll be saving the index k that maximizes the formula into bestPaths so that we
not only know the best probability at every step but also keep track of what tag resulted in the best probability.
This is what this will look like in Kotlin:
private fun viterbiForward(
sentence: List<String>,
bestProbs: D2Array<Double>,
bestPaths: D2Array<Int>
): Pair<D2Array<Double>, D2Array<Int>> {
val updatedProbs = bestProbs
val updatedPaths = bestPaths
for (i in 1 until sentence.size) for (j in 0 until NUMBER_OF_TAGS) {
var bestProbabilityToGetToWordIFromTagJ = Double.NEGATIVE_INFINITY
var bestPathToWordI = 0
for (k in 0 until NUMBER_OF_TAGS) {
val temp_prob =
updatedProbs[k, i - 1] + ln(transitionMatrix[k, j]) + ln(emissionProbsMatrix[j, vocab[sentence[i]]!!])
if (temp_prob > bestProbabilityToGetToWordIFromTagJ) {
bestProbabilityToGetToWordIFromTagJ = temp_prob
bestPathToWordI = k
}
}
updatedProbs[j, i] = bestProbabilityToGetToWordIFromTagJ
updatedPaths[j, i] = bestPathToWordI
}
return Pair(updatedProbs, updatedPaths)
}
Once we’ve built the matrices in the forward pass, we can easily get the highest probability - it’ll be the maximum
value in the last column. However, we are interested not in the probability number itself but in the sequence of tags
that yielded this number. In the Backward pass, we’ll use the bestPaths matrix to traceback the tags sequence that
have maximizes the probability.
Viterbi: Backward Pass
The backward pass is the final step of the Viterbi algorithm. Once we implement it, we’ll be able to use this algorithm to generate predictions for the sequence of POS tags matching any sentence.
In the previous, forward pass, we have populated two matrices - bestProbs and bestPaths- that we will now traverse
backwards to identify the sequence of tags that is the most likely for the given sequence of words.
First we need to find the highest value in the last column of the bestProbs, and get its row index K.
This value is the probability of the most likely sequence of hidden states, matching the given
sequence of words. The index K represents the hidden state that we were in when we calculated this probability. That’s
the POS tag for the last word in the sentence, so let’s record K into an array. Now we need to start backtracing the whole
sequence of tags, and we will switch to the bestPaths matrix.
In the last column of the bestPaths we locate the cell with index K. That cell contains the unique ID of the POS tag
of the previous word, so we jump there, and continue the same way thus “unrolling” the whole sequence. As we go through
the bestPaths matrix from right to left, in each cell we will find “directions” on where to go next.
Here’s what it could look like if we only had 5 words and 4 tags:

Let’s implement it in Kotlin:
private fun viterbiBackward(
sentence: List<String>,
bestProbs: D2Array<Double>,
bestPaths: D2Array<Int>
): List<String> {
val m = sentence.size
val z = IntArray(m)
var bestProbForLastWord = Double.NEGATIVE_INFINITY
val tags = tagCounts.keys.toList().sorted()
val posPredictions = mutableListOf<String>()
for (k in 0 until NUMBER_OF_TAGS) {
// finding the index of the cell with the highest probability in the last column of the bestProbs
if (bestProbs[k, m - 1] > bestProbForLastWord) {
bestProbForLastWord = bestProbs[k, m - 1]
z[m - 1] = k
}
}
posPredictions.add(tags[z[m - 1]])
// traversing the bestPaths backwards.
// each current cell contains the row index of the cell to go to in the next column
for (i in m - 1 downTo 1) {
val tagForWordI = bestPaths[z[i], i]
z[i - 1] = tagForWordI
posPredictions.add(tags[tagForWordI])
}
return posPredictions.toList().reversed()
}
Finally, we can combine all three steps of the Viterbi algorithm into one method that we’ll be able to use to predict a sequence of POS tags that best matches any given sentence according to the Hidden Markov Model that we have calculated based on our data.
fun predictPOSSequence(sentence: List<String>): List<String> {
val (initialBestProbs, initialBestPaths) = initializeViterbiMatrices(sentence)
val (updatedBestProbs, updatedBestPaths) = viterbiForward(sentence, initialBestProbs, initialBestPaths)
return viterbiBackward(sentence, updatedBestProbs, updatedBestPaths)
}
There are different ways we could evaluate the performance of this model. For simplicity let’s take per-word accuracy - how many words have been assigned correct tag out of all predictions that have been made.
fun score(testWords: List<String>, testTags: List<String>): Double {
require(testWords.size == testTags.size) { "The size of testWords list doesn't match the size of the testTags list" }
val predictions = this.predictPOSSequence(testWords)
val numberOfCorrectPredictions = predictions.zip(testTags).count { it.first == it.second }
return numberOfCorrectPredictions.toDouble() / predictions.size
}
To get a good measure of performance, we should always evaluate a model on the data that hasn’t been used during the training phase. Let’s see how this model does on the test data:
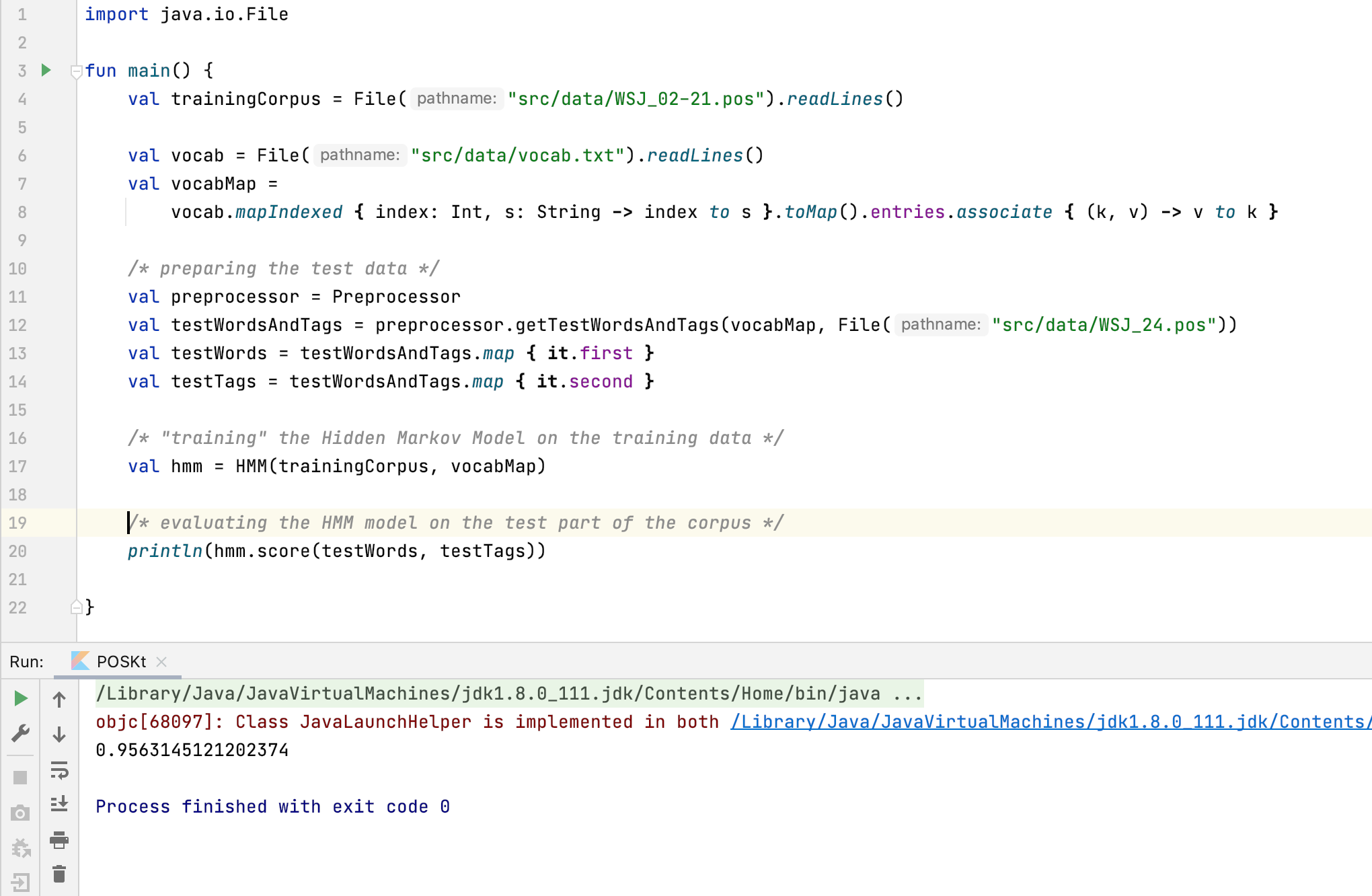
The model we’ve just build has 95% accuracy. Not too shabby! All this hard work has paid off, and you’ve reached the end of this lengthy article too. Congratulations!
PS: If you’d like to toy with the code from this article and build something of your own, feel free to check out this project on GitHub.